Последната актуализация на този раздел е от
2020 година.
5.3.4
Апаратно прогнозиране посоката на условните преходи
В отговор на
дадените в предходните пунктове насоки, тук ще се спрем на апаратното
прогнозиране на преходите и на възможностите за намаляване на загубите при
организация им.
А) Буфери и
прогнозиране на условните преходи.
Най-простата
схема за динамическо прогнозиране на посоката на условните преходи представлява
буфер за прогнозиране на условните преходи (BPB, Branch Prediction Buffer)
или таблица с “историята” на условните преходи (BHT, Branch History Table).
Тук искаме да обърнем внимание на читателя, че този проблем се дискутира
по-нататък отново в тази книга, в глава 6, пункт 6.3.1.
Буферът за прогнозиране на условните преходи представлява малка по обем памет,
чиито клетки се адресират чрез младшите разряди от адреса на командата за
преход. Всяка клетка на тази памет съдържа един бит, в който двоичната цифра
показва бил ли е предидущият преход изпълним или не. Този вид буфер не съдържа тегове
и той се оказва полезен само за съкращаване на задръжката на прехода в случай,
че тази задръжка е по-голяма от времето, необходимо за изчисляване на целевия
адрес на прехода. В действителност ние не знаем е ли прогнозата коректна
(въпросният бит в съответната клетка на буфера е могла да установи съвсем друга
команда за преход, която е имала същата комбинация в младшите битове на адреса
си). Това обаче е без значение, тъй като прогнозата е само едно предположение,
което след като се приема за коректно, извличането на машинни команди започва
именно от така определения адрес. Ако възприетото предположение се окаже
невярно, битът за изпълнимост на прехода се нулира. Разбира се такъв буфер би
могъл да се разглежда като кеш-памет, всяко обръщение към която генерира или не
попадение. Понятието кеш-памет, което се изяснява в глава 6, както и някои
други понятия, използвани в този раздел, са употребени в аванс, по
необходимост, за което се извиняваме на читателя. В този смисъл
производителността на буфера зависи от това, доколко често прогнозата е била
вярна и доколко не.
Еднобитовата схема за прогнозиране обаче има недостатъчна производителност. Нека вземем например, команда за условен преход в тялото на един цикъл, която осигурява изпълним преход последователно 9 пъти, след което се явява един неизпълним преход. Така посоката на прехода ще бъде прогнозирана неправилно при първата и последната итерация на цикъла. Неправилната прогноза на прехода при последната итерация на цикъла е неизбежна, тъй като битът, който я съдържа ще показва, че преходът е изпълним в следствие на предидущите 9 поредни изпълними преходи. Грешната прогноза при първата итерация също е неизбежна. Това се дължи на нулевото значение на прогнозния бит, установено при последната итерация на предидущото изпълнение на цикъла, когато в последната му итерация преходът е бил неизпълним. Така точността на прогнозата за прехода, който се е изпълнил в 90% от случаите, представлява само 80%. В общият случай, при команди за условен преход, използвани за организация на цикли, преходът при проверка на условието за край е последователно изпълним многократно, а при излизане един път е неизпълним. По тази причина еднобитовият признак предсказва неправилно прехода два пъти – при първата и при последната итерация (четете още поясненията свързани с фигура 6.3.1.8).
За постигане на по-добри резултати в изготвяне на прогнозата се преминава към 2-битов признак. Логиката за превключване от едното предположение към другото се състои в изискването за двукратно изпълнение на един и същ преход. Например, ако признаците съответстват на изпълним преход, то за да се преобърнат и с това да предсказват неизпълним преход, същият трябва да се случи 2 пъти подред. Логиката за изменение на прогнозните флагове се изразява с графа на тяхното превключване, представен на следващата фигура:
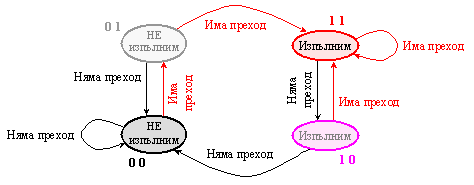
Фиг. 5.3.4.1. Граф на
превключванията на 2-битовата схема за прогнозиране
Представената
схема в действителност е частен случай на по-обща схема, в която всяка клетка
на прогнозиращия буфер се съдържа k-битов брояч. Последният може да съдържа до (2k-1)
на брой комбинации, с които градацията на надеждността на прогнозата става по
фина. В този случай логиката на прогнозиране е следната:
1.
Ако числото в брояча е по-голямо
или равно на половината (2k-1), то прогнозата е за изпълним преход
(подготвя се целевият адрес). Ако прогнозата за прехода се е оказала вярна, към
съдържанието на брояча се прибавя единица (стига то да не равно на
максималното). Ако прогнозата се е оказала невярна, тогава от брояча се изважда
единица.
2.
Ако числото в брояча е по-малко
от половината (2k-1), то прогнозата е за неизпълним преход (подготвя
се преход по съдържанието на програмния брояч). Ако прогнозата за прехода се е
оказала вярна, от съдържанието на брояча се изважда единица (стига то да не
станало равно на минималното). Ако прогнозата се е оказала невярна, тогава към
съдържанието на брояча се прибавя единица.
И в двата случая при достигане на крайните състояния на брояча същите не се променят, т.е. броячът не е кръгов.
Изследванията върху дължината на брояча показват, че увеличаването й над 2 бита не допринасят съществено за надеждността на прогнозите, ето защо дължини, по-големи от 2 бита, не се практикуват.
Буферът за прогнозиране на преходите може да бъде реализиран във вид на специализирана кеш-памет, достъпът в която се постига чрез адреса на командата за преход, по времето на началния етап в конвейера – ДК (или като двойка битове, свързани с всеки отделен блок на кеш-паметта за команди и извличани с всяка команда). Ако заредената команда се декодира като команда за преход, и ако прогнозата е той да се изпълни, то извличането на команди продължава от целевия адрес на прехода, щом той се формира и зареди в програмния брояч. В противен случай продължава последователното извличане и изпълнение. Ако прогнозата се окаже невярна, стойностите на прогнозните флагове се променя в съответствие с графа, представен на горната фигура 5.3.4.1. Въпреки, че тази схема е полезна за болшинството конвейери, разглежданият от нас тук елементарен конвейер изяснява за едно и също време двата въпроса: е ли преходът изпълним и кой е целевият адрес на прехода (предполага се, че няма конфликт при обръщение към регистъра, посочен в командата за условен преход). Ще напомним, че за простият конвейер това е справедливо, тъй като условният преход зависи от сравнението на съдържанието на регистъра с нулата, отношение, което се проверява по време на етапа АО в конвейера. По същото време се изчислява и ефективният (действителният) адрес на прехода. По този начин разбираме, че тази схема не помага в нашия случай на прост конвейер.
Както вече отбелязахме, надеждността на прогнозата при 2-битовата схема зависи от това, колко често прогнозата на всеки от преходите се оказва вярна и колко често клетката в прогнозния буфер съдържа целевата команда. Така или иначе прогнозата се извършва, въпреки че няма друга информация.
Статистическите изследвания показват, че при обем на буфера от 4096 линии точността на прогнозата на преходите в реални приложения е в интервала (82%¸99%). Трябва да отбележим, че обем от 4[K] линии за този буфер се счита за твърде голям. Буфери с по-малък обем обаче ще дадат по-лоши резултати.
Само точността на прогнозата обаче не е достатъчна, за да се определи ползата от схемата за производителността на процесора, даже ако са известни още времето за изпълнение на прехода и загубите при неправилна прогноза. Необходимо е да се отчета още честотата на самите преходи в програмата, тъй като значението на правилната прогноза в програми с голяма честота на преходите е по-голямо. Приема се, че в целочислени програми честотата на преходите е по-голяма в сравнение с честотата в програми, в които обработката е предимно с плаваща запетая.
Тъй като главната цел при конструирането на конвейерите си остава максималното използване на достъпния в програмите паралелизъм, точността на прогнозата за посоката на всеки преход се оказва много важна задача. Обработки на данни с плаваща запетая са характерни за програми, реализиращи научни изследвания. По-висока точност на прогнозите в тези случаи може да бъде достигната по два начина: чрез увеличение на обема на буфера или чрез увеличение на точността на прогнозиращата схема. Вече отбелязахме, че буфер с обем от 4[K] работи толкова добре, колкото и буфер с безкрайно голям обем. Освен това и увеличението на броя на прогнозиращите флагове също не води до желаната цел. Необходими са допълнителни идеи.
Разгледаната 2-битова схема за прогнозиране използва информация за поведението на командата за условен преход в близкото минало, за прогнозира нейното поведение в бъдеще. Съществува вероятност да бъде подобрена точността на прогнозата за прехода, който разглеждаме, ако се отчита не само неговото поведение, но още и поведението на останалите команди за условен преход. Нека разгледаме част от текста на програмата eqntott от тестовия пакет SPEC92 , имащ ниски оценки от 2-битовото прогнозиране:
if (aa==2)
aa=0;
if (bb==2)
bb=0;
if (aa!=bb) {
Генерираният
машинен код е представен по-долу (предполага се, че променливите aa и bb
са разположени в регистрите R1 и R2 съответно):
SUBI R3, R1, #2
BNEZ R3, L1 // преход първи в точка L1 (aa!=2)
ADD R1, R0, R0
// aa=0
L1: SUBI R3, R2, #2
BNEZ R3, L2 // преход втори в точка L2 (bb!=2)
ADD R2, R0, R0
// bb=0
L2: SUB R3, R1, R2
// R3:=aa-bb
BEQZ R3, L3 // преход трети в точка L3 (aa==bb).
...
L3: …
Ще
отбележим командите за управление на прехода така: К1, К2 и К3. Можем да
отбележим, че поведението на прехода К3 прилича на преходите К1 и К2. Ясно е,
че ако двата прехода К1 и К2 са неизпълними ( т.е. двете условия if се
оценяват като истинни и на двете променливи aa и bb е присвоена
стойност нула), то преходът К3 ще бъде изпълним, тъй като aa и bb
са очевидно равни. Схемата за прогнозиране, която за предсказване на прехода
използва само миналото поведение на същия този преход никога не би могла да
отчете това. Схемите за прогнозиране, които за предсказване на прехода
използват и поведението на други команди за преход, се наричат корелирани
или двустепенни схеми за прогнозиране. Схемата за прогнозиране се нарича
прогноза (1,1), ако тя използва поведението на един от последните преходи за
избор измежду двойка еднобитови схеми за прогнозиране на всеки преход. В общия
случай схема за прогнозиране (m,n) използва поведението на последните m на брой
преходи за избор измежду 2m схеми за прогнозиране, всяка от които
представлява n-битова
схема за прогнозиране на един преход. Корелираните схеми за прогнозиране са
привлекателни с това, че повишават точността на прогнозата в сравнение с
2-битовата схема и в същото време увеличават апаратните разходи незначително.
Простотата на апаратната схема се определя от това, че глобалната история на
последните m прехода би могла да бъде записана в един m-битов изместващ регистър, всеки разряд от
който запомня бил ли е преходът изпълним или не. При това положение буферът за
прогнозиране на преходите би могъл да се индексира (адресира) чрез конкатенация
на младшите разряди от адреса на прехода с m-битова глобална история. Казаното
е илюстрирано чрез схемата от следващата фигура 5.3.4.2, на която е показана
схема за прогнозиране (2,2) и организацията на извличането на битовете на
прогнозата.
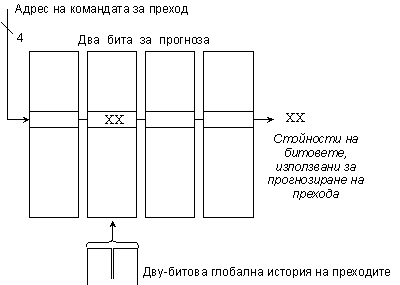
Фиг. 5.3.4.2. Буфер за
прогнозиране на преходи (2,2)
В тази
реализация съществува един трудно забележим ефект, който искаме да посочим: тъй
като буферът за прогнозиране не представлява кеш-памет, броячите, индексирани с
единствената стойност на глобалната схема за прогнозиране, могат в
действителност в някой момент да съответстват на различни команди за преход.
Това не е по-различно от онова, което вече сме виждали – прогнозата може да не
съответства на текущия преход. В структурата от фигура 5.3.4.2, с цел простота
и яснота, буферът е изобразен като двумерен обект. В действителност той се
реализира като линеен масив от 2-битова памет. Индексацията на клетките се
изпълнява чрез конкатенация на битовете на глобалната история и необходимия
брой битове от адреса на прехода. Например, в буфера (2,2), с общо 64 реда,
четирите младши разряда на адреса на командата за преход и 2 бита от глобалната
история, формират 6-битовия индекс (адрес), който може да се използва за
обръщение към един от 64-те брояча. За да бъде оценена работата на схемата с
корелация тя следва да се сравни със обикновената 2-битова схема. И за да бъде
това сравнение справедливо, е необходимо сравнението да се извърши при еднакъв
брой битове на състоянието. Броят на разрядите в схемата за прогнозиране (m,n)
е равно на 2m, където n е броя на редовете в буфера, достъпни чрез
адреса на прехода. Така например, 2-битовата схема без глобална история е
просто схема (0,2). По-горе тук беше коментиран буфер за прогнозиране с обем
4[K] реда, адресирани чрез адреса за преход. Тогава общият брой битове е: (20)*2*4[K]=8[K].
В същото време схемата от фигура 5.3.4.2 има (22)*2*16=128 бита.
За
да сравним производителността на схемата с корелирано прогнозиране с
обикновената 2-битова схема за прогнозиране, е необходимо да определим броя на
редовете в схемата с корелирано прогнозиране, или с други думи трябва да
определим броя на редовете, избирани от командата за преход в схемата за
прогнозиране (2,2), която съдържа 8[K] бита в буфера за прогнозиране.
Ние
знаем, че (22)*2*(Q)=8[K],
където Q означава – броя на
редовете, избирани от командата за преход. Ето защо, боят на редовете Q,
избирани от командата за преход е: Q = 8/((22)*2) = 1[K].
Сравненията на схемите за прогнозиране върху едни и същи приложни програми
показват във всички случаи превъзходство на схемата за прогнозиране (2,2) с
1[K] реда, над обикновената 2-битова схема с 4[K] реда. Това важи даже в
случаите, когато обикновената 2-битова схема за прогнозиране има неограничен
брой редове. Съществуват множество корелационни схеми за прогнозиране, но сред
тях, схемите (0,2) и (2,2) си остават най-интересните.
Б) По-нататъшно намаляване на задръжките – буфери на целевите адреси за преход.
Ще разгледаме
ситуация, при която по време извличането на командите се среща команда за
преход (става дума за така наречения предварителен анализ, за който подробно ще
бъде говорено в глава 6). Естествено е в този
случай, с цел съкращаване на загубите, да се интересуваме колкото се може
по-рано от целевия адрес на прехода, от който ще се извлича следващата команда.
Това означава, че трябва по някакъв начин да изясним, че още недешифрираната
команда, всъщност представлява команда за преход, и кой е целевият адрес
(последният трябва да се зареди в програмния брояч). Ако всичко това ние знаем,
то загубите в конвейера от командата за преход, могат да бъдат сведени до нула.
За целта се реализира специализирана кеш-памет, в която се съхранява
прогнозираният адрес на следващата команда. Тази памет се нарича буфер на
целевите адреси за преход (BTB,
Branch Target Buffer).
Всеки ред на този буфер съдържа програмния адрес на командата за преход, прогнозирания адрес на следващата команда и предисторията на командата за преход. Опростен вариант на логическата структура на този BTB-буфер е показан по-долу на фигура 5.3.4.3.
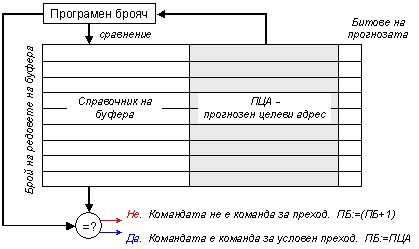
Фиг. 5.3.4.3. Структура на буфера на целевите адреси за преход
Битовете на предисторията представят информацията за изпълнението или неизпълнението на условния преход от дадената команда в миналото. Обръщението към буфера с прогнозните целеви адреси на прехода се извършва с помощта на текущото съдържание на програмния брояч още по време на зареждането на командата. Претърсването на справочната част на буфера представлява асоциативно търсене на съвпадение (наличие на командата за преход). Операция асоциативно търсене и структурата на асоциативната памет читателят може да разгледа в глава 4 на тази книга. Ако в справочната част се открие съвпадение (според терминологията на кеш-паметта, изложена тук в глава 6), според предисторията на командата се прогнозира изпълнение или неизпълнение на условието за преход. В първия случай програмният брояч се зарежда с целевия адрес, който се извлича от онзи ред на буфера, в който е открито съвпадението, в противен случай съдържанието на програмния брояч не се променя. След което следва доставката в конвейера на следващата команда. Това е първата команда от така избрания клон на програмното разклонение. Приема се, че предисторията на прехода отразява предходното двукратно изпълнение на командата за преход, според логиката на 2-битовия прогнозен автомат, който вече изяснихме (вижте по-горе фигура 5.3.4.1).
Съществуват варианти на така изложения подход за ускоряване на прогнозирането. Основната идея се състои в това, че допълнително в процесора може да се съхранява една или няколко последователни команди от прогнозирания клон на прехода. Този подход може да се приложи както в комбинация с ВТВ-буфера, така и без него и има две преимущества. Най-напред той позволява да се изпълняват обръщения към буфера на целевите адреси за преход в течение на по-дълго време, а не само в течение на такта на последователното извличане на командата. За целта обема на буфера следва да се увеличи. На второ място буферизацията на самите целеви команди позволява да се изпълни допълнителен метод за оптимизация, който се нарича свиване (съкращаване) на преходите (BF, Branch Folding). Свиването на преходите позволява времето за изпълнение командите за безусловен преход да бъде сведено до нула (вижте допълнително обясненията за буфериране на машинните команди в глава 6). В някои случаи това може да се постигне и за условните преходи. Нека разгледаме буфера на целевите адреси за преход, в който са буферирани командите от прогнозирания клон на програмата. Ако към него се извършва обръщение по адрес на команда за безусловен преход, чиято единствена задача е да подмени съдържанието на програмния брояч, то в буфера ще се регистрира съвпадение и управлението на конвейера ще подмени командата за безусловен преход (извлечена от кеш-паметта за команди) с команда от ВТВ-буфера, която е първата команда от целевото продължение. В някои случаи точно по този начин можем да премахнем загубите в конвейера от команди за условен преход, ако кодът на условието за преход е известен отнапред. Имат се предвид онези условия, които използват командите за условен преход, а те се намират в регистъра на признаците и са резултат от предидущи операции.
Съществува още един метод за намаляване на загубите от команди за преход, използващи косвено адресиране на прехода. Вече изяснихме по-рано тук в пункт 5.2.1, че косвеното адресиране е свързано с едно предварително обръщение към паметта. Тези преходи са свързани с променлив по време на изпълнението на програмата (в режим на реално време – run time) адрес. Компилаторите от езици на високо ниво ще генерират такива преходи за реализация на косвено извикване на подпрограми и процедури, за оператори select или case и за изчисляеми оператори go to във езика Fortran. Повечето косвени преходи обаче възникват в процеса на изпълнение на програмите при организация на връщането от процедури. В някои тестови пакети средният брой косвено преходи достига до 85%.
Въпреки че връщанията от процедури могат да се прогнозират с помощта на буфера на целевите адреси за преход, точността на това прогнозиране може да се окаже ниска, ако процедурата се извиква от няколко места на програмата или извикванията й от едно и също място на програмата не се локализират в паметта по време. За да се преодолее този проблем се предлага използването на неголям по обем буфер на адресите за връщане, работещ като стек. В тази структура се кешират последните няколко адреса за връщане: по време на извикване на процедура адресът за връщане се вмъква в стека, откъдето при връщане се извлича. Ако този кеш-буфер е достатъчно голям (например, толкова голям, че да осигури максимална вложеност на извикванията), той би прогнозирал отлично преходите при връщане от процедури. Тъй като на практика дълбочината на влагане обикновено не е голяма, даже с неголям по обем буфер е възможно да се достигне висока степен на точност.
Схемите за прогнозиране на условните преходи са ограничени както от точността на прогнозата, така и от загубите в случаите на грешна прогноза. Така в зависимост от типа на самата програма и от размера на буфера точността варира в границите от 80% до 95%. Освен увеличаване на точността на прогнозата като алтернатива може да се преследва още намаляването на загубите от грешна прогноза. Обикновено това се прави чрез предварително извличане на команди и от двата клона на условния преход (по предсказания и по непредсказания). Това обаче изисква извличане на команди последователно и от двата клона, или изисква системата на паметта да бъде двупортова, да включва кеш-памет с разслоение. Въпреки че такава организация увеличава цената на системата, това е единственият начин за намаляване на загубите при условен преход под определено ниво.
Като друга алтернатива, в някои машини се прилага кеширане в целевия буфер на адресите или командите от няколко разклонения.
Следващият раздел е: