Последната актуализация на този раздел е от 2020 година.
5.5.3.1 Шинно-мостова архитектура на
входно-изходната система. Архитектура PCI Express. Кодиране
8b/10b.
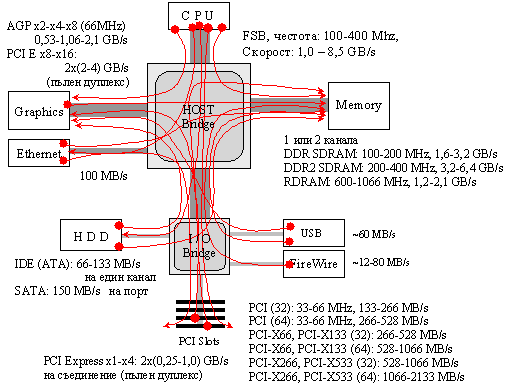
Вероятно читателят вече е добил обща представа за сложността на трафика от информация, който се реализира върху дънната платка на една компютърна платформа. Опит за нейното онагледяване е представен малко по-долу на фигура 5.5.3.1.6. Този трафик се управлява от множество контролери, които съвременната технология интегрира (обединява) в схеми, наричани чипсет (набор от чипове). Чипсетът е създаден като комуникационен център, който контролира трафика на информация върху дънната платка на всяка компютърна платформа, а така също по този начин определя какви компоненти са съвместими с дадената дънна платка и в какво количество – какъв процесор, каква оперативна памет и в какъв обем, колко дискови устройства и с какъв интерфейс, графични карти и пр.
Хардуерното осигуряване на тези архитектури се изгражда около една централна магистрала. Отделните самостоятелни елементи на системата се подключват към нея чрез шинни съгласуватели, наричани мостове. Така нареченият северен мост свързва процесора с бързите елементи в системата, като контролерите на паметта (ОП), контролер на PCI шината. За връзка с по-бавните елементи северният мост е свързан с южния, който управлява трафика с PCI слотовете, SATA и IDE конекторите, USB портовете, мрежова комуникация, аудио и пр.
Ще представим за начало структурата, разпространена през 90-те години, която се изгражда въз основа на чипсет Intel 440 AGPset. Наборът от контролери в него е оптимизиран за еднопроцесорни системи, но поддържа симетрична (Symmetric Multiprocessor Protocol - SMP) двупроцесорна конфигурация върху шината HostBus за процесори Pentium II и Pentium III. Този чипсет се състои от две интегрални схеми:
· 82443ВХ System Controller (TXC), затворена в 324-pin BGA корпус ;
· 82371ЕВ PCI ISA IDE Accelerator (PIIX4E), затворена в 208-pin PQFP корпус.
Наборът
се характеризира още със следните параметри: тактова честота на процесорната
шина 100[MHz]; 64-битова разрядност на HostBus и AGP; осъществява контрол по
четност на данните и контрол на захранването. Управлява модули памет
PC100-SDRAM с обем от 16[MiB] до 2[GiB]. Има функциите Bus Mastering, UltraDMA/33, Power Management,
контролер за прекъсвания APIC, шинни интерфейси PCI 2.1, AGP 1.0 с режими
х1/х2, интерфейс за шина USB и други функции и устройства. Общата структура на
системата е показана на следващата фигура.
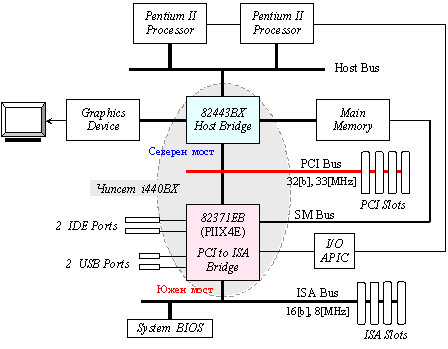
Фиг. 5.5.3.1.1. Системна архитектура с чипсет i440ВХ
Северният мост осигурява интерфейса с процесорите, с оперативната памет, с видеокартата и с южния мост, т.е. свързва бързата процесорна шина (400/266/200/133/100/66 [MHz]) с по-бавните шини AGP (533/266/133/66[MHz]) и PCI (66/33[MHz]). Интерфейсът с процесора е FSB, а с видеокартата - AGP или PCI Express x16. Интерфейсът с южния мост има специално наименование, на което ще се спрем по-късно. Оперативната памет се управлява от контролера на паметта, който се съдържа в северния мост. Когато процесорите имат съответната конструкция за монтаж (например сокет 754, 939 и 940), контролерът е интегриран в корпусите на процесорите и тогава връзката на оперативната памет с процесора е директна, както е показана на фигура 5.5.2.15. Централният процесор не адресира непосредствено паметта или видеокартата. Тези функции се реализират от съответните контролери, вградени в северния мост. По тази причина северният мост е определящ за производителността на системата. Ако работните параметри на даден модел северен мост с паметта са по-добри от тези на друг, то системата, управлявана от първия, ще осигурява гарантирано по-висока производителност. Когато контролерите на паметта са интегрирани в процесорите, възможността чипсетите да им влияят почти отсъства, ето защо и влиянието им върху производителността на системата като цяло е слабо. Северният мост първоначално поддържа интерфейса на шината PCI и като интерфейс за връзка с южния мост. Тази връзка представлява второто ниво в шинно-мостовата архитектура на входно-изходната система.
Южният мост се нарича още I/O Controller Hub (входно-изходен контролер). Той съдържа контролер за директна връзка със северния мост и е отговорен за производителността на входно-изходните устройства и допълнителните функции, интегрирани на дънната платка. С други думи той свързва системната шина PCI (66/33[MHz]) с периферните шини, като е отговорен за интерфейсите на наличните портове за твърди дискове (Parallel ATA и Serial ATA), както и за USB-портовете (Universal Serial Bus) и за LAN-интерфейса (Local Area Network); той контролира функциите на вградените звукова и мрежова карти; към него директно са свързани средно и високо производителни шини PCI и по-новата PCI Express. Освен с тях южният мост е свързан с BIOS ROM паметта и с интегралната схема Super I/O. В тази интегрална схема са обединени контролерите на ниско скоростните интерфейси: за PS/2 (клавиатура, мишка), за последователни СОМ-портове (един или два), за паралелен порт (LPT – Line Parallel Transport), за джойстик или за MIDI, за флопидискови устройства. Съвременните системни платки съдържат тези контролери обикновено в южния мост и се свързват с високите нива на системата чрез шина LPC (Low Pin Count).
Южният мост не е толкова значим за производителността на системата. Тъй като в северния мост са съсредоточени високоскоростни контролери, той обикновено е снабден с радиатор за охлаждане. В същото време южният мост или няма такъв, или той е твърде скромен. Ограниченията, които южният мост налага на системата, се отнасят до максимално възможния брой на USB портовете, на интерфейсите за твърди дискове и пр.
Разделянето на необходимата апаратна логика върху дънната платка и интегрирането й в две големи интегрални схеми не е случайно. Съображенията за това са следните: на първо място, колкото по-близо е съединителното гнездо до контролера, толкова по-лесна е разводката на съединителните линии и толкова по-стабилно работи интерфейсът (шината). По тази причина северният мост е разположен така, че до него да са в най-голяма близост съединителят на процесора, видео-съединителят AGP (PCI Express) и съединителите на модулите оперативна памет. На свой ред, южният мост се намира близо до съединителите на PCI шината, до съединителите SATA и PATA, а така също до USB портовете.
Връзка
между мостовете
Първоначално шинните мостове са свързвани чрез PCI шината. При тактова честота от 33[MHz] скоростта за трансфер, която следва да споделят всички подключени устройства е 132[MiB/s]. Тъй като по това време скоростта за трансфер на твърдите дискове беше от порядъка на 16 до 33[MiB/s], подобно решение е било напълно приемливо.
С появата на по-нови видеоускорители идеята да се споделя една обща PCI шина за цялата комуникация между всички устройства в системата, среща съпротива от страна на производителите. Проблемът се състоеше в това, че ускорителите осигуряваха значително по-високи скорости от тези върху PCI шината. Тази ситуация доведе до създаване на допълнителна шина, наречена AGP. AGP слотът беше веднага директно свързан със северния мост. Така беше решен първия проблем с ограничаването на производителността в шинно-мостовата архитектура.
След бързите графични ускорители се появиха и бързите твърди дискове. Те от своя страна отново показаха, че PCI шината е тясна за максималният им теоретичен трансфер. На практика едно АТА/133 устройство със скорост на трансфер от 133[MiB/s] е способно за “задуши” бавния трансфер на останалите PCI устройства. Крайното решение, което производителите взеха, бе PCI шината да бъде генерирана от южния мост, а той самият да комуникира със северния чрез специална високо скоростна шина. Тази архитектура е запазена и до наши дни, като нейната производителност зависи от модела на чипсета – така например Intel 925X предлага максимална скорост на обмен от 2[GiB/s].
Връзката между двата моста представлява основният проблем и недостатък на шинно-мостовата архитектура. Минимизирайки разстоянията между двата моста, производителят SiS стигна до там, че ги затвори в една интегрална схема. Скоростта на вътрешната връзка в такава схема е наречена MuTiOL и тя достига скорост на трансфер до 1[GiB/s]. Структурата на компютърна система на базата на чипсета SiS 735 е показана на фигура 5.5.3.3.2.
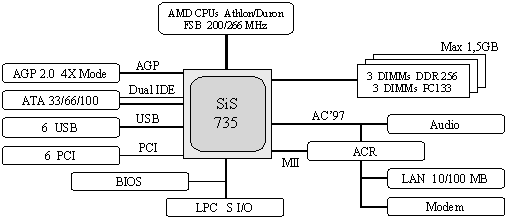
Фиг. 5.5.3.1.2. Системна архитектура с чипсет SiS 735
Разбира се технологиите не спряха на това ниво и днес сме свидетели на системи с разделни мостове, имащи още по-висока скорост на обмен.
Интеграция
на мостовете
С развитието на технологиите процесорната схема интегрира в себе си голяма част от контролерите, които традиционно се обединяваха в северния мост, като тези свързани с паметта, с графиката и пр. Пример за това е показаната по-долу платформа на базата на процесор на Intel (Core i7).
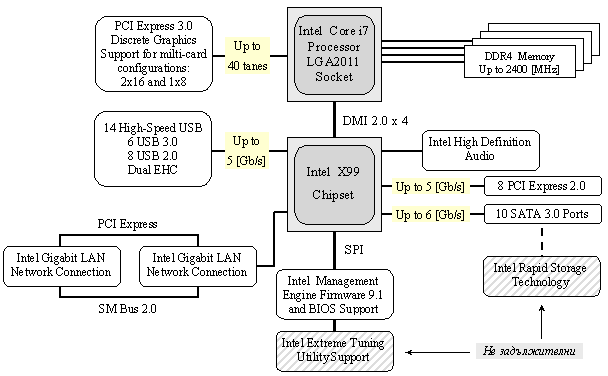
Фиг. 5.5.3.1.3. Системна архитектура с интегриран северен мост
В
системите на Intel южният мост вече се нарича Platform
Controller Hub или PCH. PCH е свързан към процесора чрез Direct
Media Interface или DMI.
Чипсетите на AMD също извървяха тази еволюция. Южният мост вече се нарича Fusion Controller Hub или FCH. Тази
схема е свързана директно с процесора, а връзката се нарича Unified Media
Interface или UMI.
Много от
различните видове процесори на Intel и AMD се предлагат с
вградени графични контролери, така че потребителят на компютърни платформи не
се нуждае от отделна графична карта (освен в случаите, когато ще играете игри
или ще редактирате видео файлове).
Хибридни процесори
Във връзка с тези
възможности се появиха нови термини и определения, които желаем да споменем.
Например, започна да се говори за хибридни процесори (APU – Accelerated Processing Unit), и още
(HSA – Heterogeneous System Architecture). Под
това наименование следва да се разбира интегрална схема, която обединява върху
една кристална подложка многоядрен изчислителен процесор (CPU) и графичен процесор (GPU). Ето
отправни точки за любознателния читател, който желае допълнителна информация:
https://en.wikipedia.org/wiki/AMD_Accelerated_Processing_Unit ,
https://en.wikipedia.org/wiki/Heterogeneous_System_Architecture
.
Както вече беше
споменато, при подобно обединяване, отпада необходимостта от северен мост
в компютърната архитектура. Основните достойнства на хибридните процесори, в
сравнение с останалите, се състоят в следното:
1.
Постига се висока компактност на компютърната
платформа ;
2.
Повишава се надеждността на платформите с
хибриден процесор ;
3.
Отсъствието на отделна видеокарта повишава
производителността на системата и намалява шума, тъй като липсва вентилатор за
последната ;
4.
Снижава енергийния разход на платформата и
подобрява охлаждането на системата.
Платформите с
хибридни процесори имат и някои недостатъци:
1.
Не е възможен ъпгрейд на видеопроцесора отделно
от централния ;
2.
Снижена производителност, тъй като
видеопроцесорът не разполага със собствена памет и се налага да използва
общата.
И както винаги сме
отбелязвали, докато излагаме тази информация, се явяват нови решения. Така
например, току що се появи съобщение, че компания Intel предлага 5-ядрения хибриден процесор Lakefield с 3-D компановка Foveros. Процесорът Lakefield съдържа
5 ядра – едно ядро Core i3 или Core i5 плюс още 4 ядра Atom. По
тази причина процесорът има означението (1+4).
Обемната 3-D компановка Foveros е
илюстрирана на следващата рисунка:
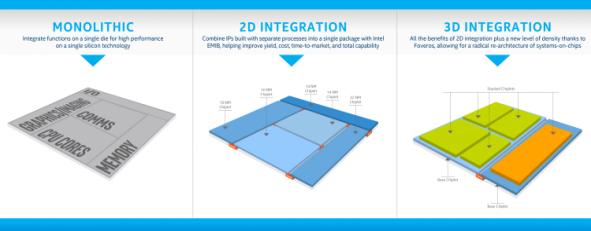

Ядрото Core (Sunny Cove) е оборудвано с
512[KiB] кеш памет L2.
Четирите ядра Atom (Tremont) се поддържат от обща кеш памет L2 с обем 1536[KiB]. Цялата
изчислителна структура се поддържа от обща кеш памет L1 с обем от 4[MiB].
Видеопроцесорът съдържа 64 графични ядра тип Gen11.
Всички елементи в
хибридната структура Intel
произвежда по оптимизирана 14-нанометрова технология. Обемното съединяване на
схемите се осъществява по технология, която е означавана (Die-to-Die).
Няма да се впускаме в повече подробности,
тъй като отново излизаме от контекста на нашата тема. Подробностите читателят
може лесно да намери в научните и в информационните публикации.
Изложихме кратко
същността и развитието (до момента) на шинно-мостовата архитектурата на
входно-изходната система на компютърните системи. Изложението по темата
архитектура на чипсета може да бъде неимоверно задълбочено, в което ние тук
няма да се изкушим, тъй като това не отговаря на нашите цели. Читателят може да
с лекота да достигне публикациите с достатъчно нови и достатъчно подробни
описания и сравнения на параметрите на тези интегрални схеми, предлагани от
редица производители. Комбинацията от процесор и чипсет е също достатъчно
разнообразна, което се изявява в множеството различни дънни платки, имащи
разнообразна производителност, целяща да задоволи различните възможности на
потребителите.
Пълен списък на произвежданите по години от компания Intel чипсети читателят може да намери по следния адрес:
https://en.wikipedia.org/wiki/List_of_Intel_chipsets
Пълен списък на произвежданите по години от
конкурентната компания AMD чипсети читателят може
да намери по следния адрес:
https://en.wikipedia.org/wiki/List_of_AMD_chipsets
Шина
PCI Express
Отново
следва да предупредим читателя, че нашето изложение по темата тук е
образователно, а не изследователско. По тази причина то ще бъде кратко и
свързано с най-общите характеристики на описваните обекти. Пълен план на
описанието на високо скоростната серийна връзка, наречена PCI Express (Peripheral Component Interconnect Express),
читателят може да намери по следния адрес:
https://en.wikipedia.org/wiki/PCI_Express
PCI
Express връзката представлява преход в организацията на трансфера на данни от
паралелна към серийна комуникация. Организацията на паралелен трансфер разбира
се е най-добрата, но при нея се срещат някои проблеми, които пречат за
достигане на по-висока тактова честота. Колкото по-висока е честотата,
по-големи ще са и проблемите с електромагнитните смущения (EMI) и забавяне на
разпространението. Други съвместими интерфейси, използващи серийна комуникация
включват USB, Ethernet, както и SATA и SAS.
Първоначално
ще поясним някои разбирания, свързани с наименованията PCI и PCI Express.
1.
PCI
(Peripheral Component Interconnect) е шина, а PCI Express
(Peripheral Component Interconnect Express) е връзка от точка
до точка, т.е. тя свързва само две устройства и няма друго устройство,
което да може да сподели тази връзка. На дънна платка, използваща стандартен
PCI слот, всички PCI устройства са свързани към PCI шината и споделят един и
същ път за данни. На дънна платка използваща стандартен PCI слот, всички PCI
устройства са свързани към PCI шината и споделят една и съща пътека за данни.
На дънна платка с PCI Express слотове, всеки PCI Express слот е свързан
към чипсета чрез специална лента, не споделящ тази лента с други PCI Express
слотове. Също така устройства, интегрирани на дънната платка, като SATA и USB
контролери, обикновено са свързани към чипсета с помощта на специални PCI
Express връзки ;
2.
PCI и всички други разширителни слотове
използват паралелни комуникации, докато PCI Express се основава на
високоскоростна серийна комуникация ;
3.
PCI Express се основава на отделни ленти,
които могат да бъдат групирани за създаване на по-висока пропускателна
способност. Символът “х”, който следва описанието на PCI Express връзката, се
отнася до броя на лентите. Спецификацията на PCI
Express позволява слотовете да имат различни физически размери, в зависимост от
броя на пътеките, свързани към слота:

Ето всички слотове за разширение, обявени за компютърни платформи, използвани в годините:
·
ISA (Industry
Standard Architecture) ;
·
MCA (Micro
Channel Architecture) ;
·
EISA (Extended
Industry Standard Architecture) ;
·
VLB (VESA
Local Bus) ;
·
PCI (Peripheral
Component Interconnect) ;
·
PCI-X (Peripheral
Component Interconnect eXtended) ;
·
AGP (Accelerated
Graphics Port) .
·
PCI Express (Peripheral Component Interconnect Express) .
В следващата таблица са представени основни спецификации за някои от разширителните слотове върху дънните платки, произвеждани в годините.
|
Slot |
Bits |
Clock |
BandWidth |
|
ISA |
8 16 |
4,77[MHz]
8[MHz] |
4,77[MiB/s] 8[MiB/s] |
|
VLB |
32 |
33[MHz] |
133[MiB/s] |
|
PCI-X
533 |
64 |
66[MHz] |
4,266[MiB/s] |
|
AGP
x8 |
32 |
66[MHz] |
2,133[MiB/s] |
|
PCIe
2.0 x16 |
16 |
5[GHz] |
8[MiB/s] |
|
PCIe
3.0 x16 |
16 |
8[GHz] |
16[MiB/s] |
|
PCIe
4.0 |
128 |
16[GHz] |
2[GiB/s] |
Посочените в горната таблица данни не са последни. Например, за PCIe 5.0 последният параметър достига стойността 8[GiB/s]. Очаква се (2021 година) следващият стандарт PCIe 6.0 да осигури скорост от 256[GiB/s], което вече е впечатляващо! С подобни параметри, както ще видим по-надолу, много от посочените проблеми ще бъдат успешно преодолени.
Отново назад във времето - ще се спрем кратко на една от основните стандартни шини и следствията от нея. Към момента на отпечатването на първоначалния вариант на тази книга (2008 година) все още в сила беше стандартът PCI Express 2.0, който беше финализиран през 2006 година. Подробности читателят може да намери на следния адрес:
http://www.pcisig.com/specifications/pciexpress/base2/
В настоящият момент, предлагаме на читателя, като най-удачен за начален обзор на темата, адреса:
https://en.wikipedia.org/wiki/PCI_Express
Основната вътрешна шина на
съвременните дънни платки е PCI Express (PCIe) (Peripheral Component Interconnect Express). Както вече писахме по-горе, PCIe
използва “линии” (или още канали), които позволяват на вътрешните компоненти
като RAM и разширителни карти да комуникират с процесора и обратно. Каналът (PCI Express Link), чиято схема ще представим по-надолу, представлява две двойки от кабелни
връзки – единия чифт изпраща информация, а другия получава информация. PCIe x1
линията се състои от четири кабелни връзки, PCIe x2 има осем и така нататък.
Колкото повече кабелни връзки има, толкова повече данни може да се обменят.
PCIe x1 може да трансферира 250[MiB]
във всяка посока, PCIe x2 може да трансферира 512[MiB] и т.н.. системната шина PCIe
представлява съвкупност от самостоятелни серийни двупосочни канали за предаване
на данни, обединени по топологията "звезда". Всички канали от едната
страна са подключени към комутатор (switch), разположен в центъра на звездата. От другата страна на всеки канал е
подключено едно устройство, участващо в обмена. По този начин, между всяко
устройство и комутатора се реализира връзка, наричана “точка-точка” ((Point-to-Point)). Така, посредством комутатора, всяко
устройство може да бъде свързано с друго устройство.
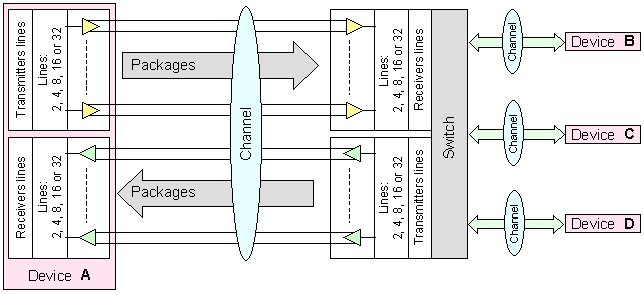
Фиг. 5.5.3.1.4. Организация на системна шина въз основа
на стандарта PCI Express
Шината
PCIe предава информацията в пакети, които могат
да съдържат данни, адреси, служебни данни, запитвания и пр. При това всички
видове пакети се предават по едни и същи линии. Обменът на информация протича
едновременно (но не и синхронно) по всички достъпни линии. Така например, за
канала с 4 линии първият предаван пакет може да бъде изпратен по първа линия,
вторият – по втора линия, третия – по трета линия, четвъртия –по четвърта
линия, а петия пакет ще бъде изпратен отново по първа линия и т.н. Всяка линия
функционира независимо от другите линии, за сметка на което се постигат тези
високи скорости на трансфер. Шината използва протокол с разделяне на
транзакциите. В каналите с защита на данните се прилага кодиране с излишък, при
което всеки байт се представя с 10 битова комбинация. За всичко това е написано
по-надолу. Цялата организация на шината PCIe се управлява от контролер (Host Bridge) съответстващ на устройство А в горната фигура.
Ключовите атрибути на PCI, като например нейният модел за използване и програмният интерфейс, се запазват. В същото време нейната реализация с ограничена пропускателна способност и паралелна архитектура се заменят с последователна. Протоколът на разцепените транзакции (split-transaction protocol) се реализира с поддръжка на пакети, притежаващи набор от атрибути, които определят назначаването на приоритетите и се доставят до целта по оптимален начин. В режим х16 шината ще може да осигурява скорост до 16[GiB/s]. Стандартът е предназначен за широк набор от форм-фактори за да осигури съвместимост със съществуващите системи.
Шината PCI, както и едни от най-добрите следващи нейни версии PCI 2.2 и PCI-X, поддържат компютърните системи вече повече от 20 години. В множество системи, произведени в следващите години обаче се наложи използването на нови и по-производителни шини, в резултат на което архитектурата им доби следния вид:
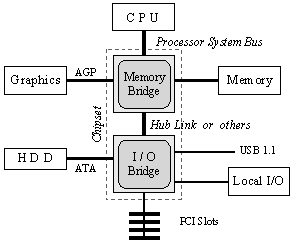
Фиг. 5.5.3.1.5. Традиционна шинно-мостова архитектура
Динамиката в еволюцията на системите е такава, че процесорната шина постоянно се намира в процес на мащабиране както по честота така и по напрежение. Пропускателната способност на паметта също се увеличава, за да съответства на изискванията на процесора. Съответно, както е показано по-горе на фигурата, поддържащият хардуер в лицето на чипсета обикновено съдържа две части – концентратор на паметта и концентратор за входно-изходната система. По този начин се постига изолиране (отделяне) на динамичната северна част от по-стабилната южна част на системата, към която и остава причислена паралелната PCI шина. Всички опити да се повиши производителността на паралелната PCI шина бяха опорочавани от явлението skew (изкривяване), за което писахме предидущия пункт 5.5.2. Освен това множеството PCI разновидности се оказват несъвместими помежду си. Съвременните приложения са зависими от апаратните средства във входно-изходната система в по-висока степен. Обработката например на потоци от данни от различни аудио и видео източници вече представляват съществена част за мобилните и настолните системи. В стандартите PCI 2.2 или PCI-Х нямаше вградени механизми, поддържащи свързани по време данни. Много приложения са зависими от събиране и обработка на данни в режим “реално време”, да обработват няколко конкуриращи се потоци от данни от различни източници. Ето защо данните следва да бъдат маркирани по такъв начин, за да може входно-изходната система да им назначава правилен приоритет за обработка.
На фигура 5.5.3.1.6 са показани (с точка) инициаторите на транзакции в главните потоци от данни и целевите устройства (със стрелки). Потоците могат да бъдат в двете направления. От рисунката може да се направи изводът, че главен компонент в системата е оперативната памет.
Фиг. 5.5.3.1.6. Потоци от данни в компютърната система
Анализът на натрупания опит води до следните изисквания към новото поколение входно-изходни системи:
· Универсалност: изискване за унификация на входно-изходната архитектура за настолни, мобилни, сървърни, вградени и комуникационни системи. По този начин поддържа множество пазарни ниши и “плуващи” приложения ;
· Ниска стойност: цената следва да бъде съвместима с тази, на съществуващите системи с шини от стандарта PCI ;
· Програмният модел да е съвместим със съществуващия PCI модел: това означава, да се запази без изменение зареждането на съществуващите операционни системи, а така също да се запази съвместимостта на PCI конфигурацията и интерфейса на системните драйвери ;
· Производителност: мащабируема производителност чрез увеличаване на честотата и броя на каналите за предаване на данни ;
· Поддръжка на множество платформени крайни интерфейси от тип точка-точка, платка към платка и към работна станция чрез конектор. Позволява нови форм-фактори ;
· Допълнителни характеристики. Различава различни типове данни. Позволява управление на захранването, на качеството на обслужването. Поддържа технологии “хот-плъг” и “хот-свап”. Прави системата свободно разширяема. Притежава основен механизъм за внедряване на комуникационни приложения ;
· Осигурява кохерентност на връзките в памети, в многопроцесорни и в клъстерни системи.
Последните достижения във областта на високо скоростните и в същото време малко контактни технологии LPC (low-pin-count), наричани още “точка-точка”, предлагат възможности за увеличаване на пропускателната способност на входно-изходните шини. Множествените съединения от тип “точка-точка” водят след себе си появата на нов елемент в топологията на системата за вход-изход – комутатор (switch), както е показано на фигура 5.5.3.1.7. Разбира се, за да е ефективен комутаторът, той следва да свързва унифицирани интерфейси.
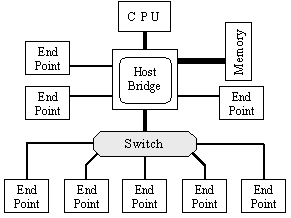
Фиг. 5.5.3.1.7. Архитектура с комутатор
Интересното в тази архитектура е това, че тя осигурява обмен на данни между крайните потребители-източници по такъв начин, че организираният от нея трафик по никакъв начин не засяга оперативната памет, ако те не изискват това специално, т.е. трафикът не засяга схемата Host Bridge.
Следващите рисунки показват типичното използване на архитектура PCI Express.
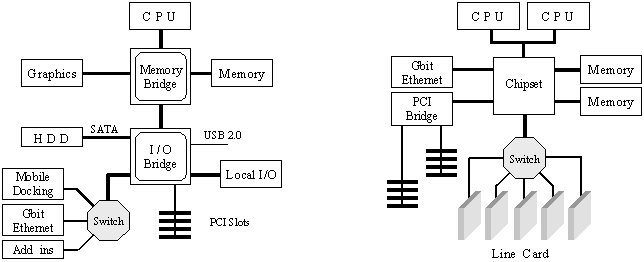
Фиг. 5.5.3.1.8. PCI Express архитектури с комутатори, типични за 2004-2005 година
Архитектурата
PCI Express
Архитектурата PCI Express се определя от няколко слоя, показани на следващата фигура 5.5.3.1.9.

Фиг. 5.5.3.1.9. Слоеве в PCI Еxpress архитектура
За осигуряване на съвместимост със съществуващите приложения и драйвери е запазен моделът за PCI адресация. За конфигуриране PCI Еxpress използва стандартен механизъм Plug-and-Play. Програмното ниво генерира заявки за четене и запис, които се предават от нивото на транзакциите към периферните устройства. Транзакциите използват пакетно ориентиран протокол с разцепване (split-transaction). Нивото “Link” добавя последователния номер и контролния код CRC, с което се осигурява надеждността при предаване. Физическото ниво се състои от два канала, които са реализирани като предаваща и приемаща двойка. Началната скорост от 2,5 [Giga transfers/s] осигурява на канала за връзка пропускателна способност от 200[MiB/s], което е почти 2 пъти повече в сравнение с PCI.
Физически
слой
Физическият слой, в който се представят данните, отговаря за достоверността при тяхното приемане в крайната точка. На това ниво на всеки пакет се присвоява пореден номер и се добавя контролна сума CRC. След приемане на данните в кодиран вид контролната сума се проверява и ако пакетът е приет с грешки, се формира заявка за повторно предаване на пакета.
Основният канал в PCI Express се състои от две ниско волтови диференциални усукани двойки – предаваща и приемаща двойка (вижте фигура 5.5.3.1.10). Едновременното изменение на потенциалите в двата проводника позволява да се намали влиянието на електромагнитните шумове.
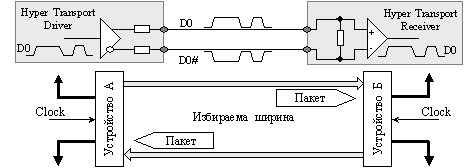
Фиг. 5.5.3.1.10. Предаваща и приемаща двойка в PCI Express връзка
Физическият слой може да се раздели на два подслоя:
1. Подслой на достъпа към средата за предаване на данни (PMA – Physical Media Attachment Sublayer) ;
2. Подслой на физическото кодиране (PCS – Physical Coding Sublayer) .
Подслоевете формират интегрирания трансивер, чиято структура е показана на следващата фигура:
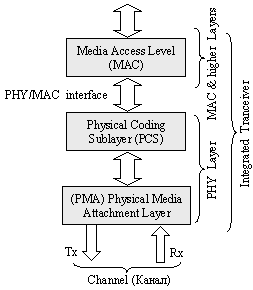
Фиг. 5.5.3.1.11. Физически слой на шина PCI Express
Поднивото на физическото кодиране е свързано с 16-битов интерфейс с по-високото ниво за достъп до средата за предаване на данни (MAC – Media Access Layer). Ето защо, първоначално получената по паралелния 16-битов интерфейс, порция данни се разделя на 2 групи от по 8 бита, върху които се прилага схемата за последователно кодиране 8b/10b, която ще бъде разгледана по-надолу. Тактовата честота на 16-битовия интерфейс е 125[MHz]. За 8-битовия става 250[MHz], а при предаване на 10-битовия код по последователната линия честотата става 2,5[GHz], както е илюстрирано на следващата фигура.
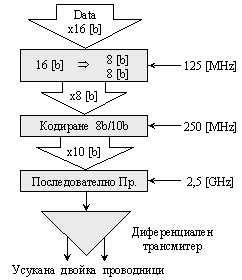
Фиг. 5.5.3.1.12. Преобразуване на данните във физическия слой при предаване
При приемане на данните на физическо ниво те претърпяват преобразуване в обратен ред. От диференциалната двойка сигналът постъпва на диференциален приемник, от изхода на който се сглобява 10-битовата комбинация. Паралелното предаване на тази комбинация става с 10 пъти по-ниска честота – 250[MHz]. От нея след логическата схема на декодера се получава 8-битовата комбинация. Изчакват се 2 такива комбинации, сглобява се 16-битовата дума, която се предава по 16-битовия интерфейс с честота, която е 2 пъти по-ниска, т.е. тя е 125[MHz].
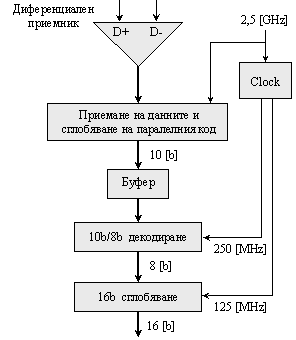
Фиг. 5.5.3.1.13. Преобразуване на данните във физическия слой при приемане
Когато се използва мащабиране в шината (х2, х4, х8, x16, x32) управлението на потока данни се контролира от специален PCI Experss елемент, който го разпределя към отделните физически устройства. Аналогичен елемент обединява различни потоци в един. Отделните байтове в канала се разпределят както е показано на следващата фигура.
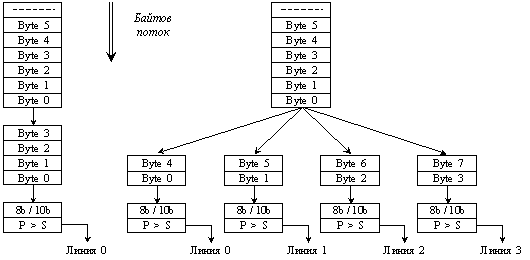
Фиг. 5.5.3.1.14. Организация на PCI Express шината при наличие на няколко магистрални линии
Предаваните данни се кодират. Методът за кодиране се нарича “8/10” и се причислява към групата на кодовете с излишък. Последователността от битове се групира в порции по 8 бита всяка, т.е. в байтове. Всеки байт се превръща в 10-битова комбинация според схемата, представена на следващата фигура:
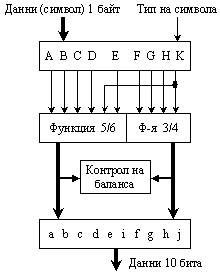
Фиг. 5.5.3.1.15. Схема на преобразованието 8/10
Представената схема е разработена от IBM и ESCON (1983 година) и позволява да се постигне баланс на напрежението на постоянния ток в усуканата двойка проводници при предаване. Балансиране означава, че в дадена последователност от битове, която се предава по връзката, броят на нулите е равен на броя на единиците. По този начин не се позволява на един от проводниците на връзката да натрупва по-голямо количество носители на електричество от другия, т.е. двете нива на напрежението да са еднакви по абсолютна стойност по отношение на нулевия потенциал. Не кодираната информация е групирана по 8 бита (означени на фигурата със символите A, B, C, D, E, F, G, H) и допълнена с контролната променлива Z. Последната може да приема стойност D в случая на обикновени символни данни (променлива D-тип) или стойност K, в случай на специални символи (променлива K-тип). В съответствие със схемата, тези символи се преобразуват във символи за предаване (Transmission Character), т.е. в двоична комбинация с дължина 10 бита (a, b, c, d, e, i, f, g, h, j). Правилата в частност предполагат, че предаваният символ от D-тип трябва да съдържа не по-малко от 4 нули и единици, при това броят на наредените подред нули и единици не трябва да са повече от 4. Всеки предаван символ, който има смисъл, има своето означение <Zxx.y> в съответствие със следната уговорка: Z – контролна променлива; xx – представлява десетичната стойност на двоичното число, образувано от битовете (E,D,C,B,A); а y – е десетичната стойност на двоичното число, образувано от битовете (H,G,F). Така например, предаваният символ за специалния (т.е. от K-тип) байт 10111100, се означава <K28.5>. Това е символът “запетая” (comma). Такива са още <K28.1> и <K28.7>. Кодовата схема може да се изрази по следния начин:
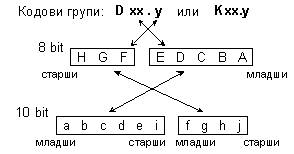
По-подробно кодовите съответствия са дадени в следващите таблици.
Таблица 5.5.3.1.1 Кодиране на 3 бита в 4 бита:
|
3[b] десетична стойност |
3[b] двоична стойност ( H G F ) |
4[b] двоична стойност ( f g h j ) |
|
0 |
0 0 0 |
0 1 0 0
или 1 0 1 1 |
|
1 |
0 0 1 |
1 0 0 1 |
|
2 |
0 1 0 |
0 1 0 1 |
|
3 |
0 1 1 |
0 0 1 1
или 1 1 0 0 |
|
4 |
1 0 0 |
1 0 1 0
или 1 1 0 1 |
|
5 |
1 0 1 |
1 0 1 0 |
|
6 |
1 1 0 |
0 1 1 0 |
|
7 |
1 1 1 |
0 0 0 1
или 1 1 1 0 или
1 0 0 0 или 0 1 1 1 |
Таблица 5.5.3.1.2 Кодиране на 5 бита в 6 бита:
|
5[b] десетична стойност |
5[b] двоична стойност ( E D C B A ) |
6[b] двоична стойност ( a b c d e i ) |
|
0 |
0 0 0 0 0 |
1 0 0 1 1 1
или 0 1 1 0 0 0 |
|
1 |
0 0 0 0 1 |
0 1 1 1 01
или 1 0 0 0 1 0 |
|
2 |
0 0 0 1 0 |
1 0 1 1 0 1
или 0 1 0 0 1 0 |
|
3 |
0 0 0 1 1 |
1 1 0 0 0 1 |
|
4 |
0 0 1 0 0 |
1 1 0 1 0 1
или 0 0 1 0 1 0 |
|
5 |
0 0 1 0 1 |
1 0 1 0 0 1 |
|
6 |
0 0 1 1 0 |
0 1 1 0 0 1 |
|
7 |
0 0 1 1 1 |
1 1 1 0 0 0
или 0 0 0 1 1 1 |
|
8 |
0 1 0 0 0 |
1 1 1 0 0 1
или 0 0 0 1 1 0 |
|
9 |
0 1 0 0 1 |
1 0 0 1 0 1 |
|
10 |
0 1 0 1 0 |
0 1 0 1 0 1 |
|
11 |
0 1 0 1 1 |
1 1 0 1 0 0 |
|
12 |
0 1 1 0 0 |
0 0 1 1 0 1 |
|
13 |
0 1 1 0 1 |
1 0 1 1 0 0 |
|
14 |
0 1 1 1 0 |
0 1 1 1 0 0 |
|
15 |
0 1 1 1 1 |
0 1 0 1 1 1
или 1 0 1 0 0 0 |
|
16 |
1 0 0 0 0 |
0 1 1 0 1 1
или 1 0 0 1 0 0 |
|
17 |
1 0 0 0 1 |
1 0 0 0 1 1 |
|
18 |
1 0 0 1 0 |
0 1 0 0 1 1 |
|
19 |
1 0 0 1 1 |
1 1 0 0 1 0 |
|
20 |
1 0 1 0 0 |
0 0 1 0 1 1 |
|
21 |
1 0 1 0 1 |
1 0 1 0 1 0 |
|
22 |
1 0 1 1 0 |
0 1 1 0 1 0 |
|
23 |
1 0 1 1 1 |
1 1 1 0 1 0
или 0 0 0 1 0 1 |
|
24 |
1 1 0 0 0 |
1 1 0 0 1 1
или 0 0 1 1 0 0 |
|
25 |
1 1 0 0 1 |
1 0 0 1 1 0 |
|
26 |
1 1 0 1 0 |
0 1 0 1 1 0 |
|
27 |
1 1 0 1 1 |
1 1 0 1 1 0 или 0 0 1 0 0 1 |
|
28 |
1 1 1 0 0 |
0 0 1 1 1 0 |
|
29 |
1 1 1 0 1 |
0 0 1 1 1 0
или 0 1 0 0 0 1 |
|
30 |
1 1 1 1 0 |
0 1 1 1 1 0
или 1 0 0 0 0 1 |
|
31 |
1 1 1 1 1 |
1 0 1 0 1 1
или 0 1 0 1 0 0 |
С цел да се създаде балансиран поток от
данни, е приложена концепцията за уравновесяване (изравняване) броя на нулите и
единиците в кодовите комбинации. Несъответствието (или още дисбалансът) на
даден пакет се определя чрез разликата между броя на единиците и броя на
нулите. Ако в един пакет разликата между броя на единиците
и на нулите е равна на нула, то той се нарича неутрален. Ако 4-битовите и 6-битовите комбинации са
неутрални, комбинираните 10-битови данни ще бъдат също в неутрално състояние.
Това ще създаде перфектно DC-балансиран код. И все пак това не е възможно,
защото само 6 от 16 възможни комбинации на 4-битовия блок са неутрални, т.е. те
не са достатъчни за кодиране на 8-те комбинации на 3-битовия блок.
Също така, само 20
комбинации на 6-битовия блок са неутрални и те не са достатъчни за еднозначно
съответствие на 32-те комбинации на 5-битовия блок. Тъй като и 4-битовите и
6-битовите блокове имат дължина от четен брой битове, не е възможно дисбалансът
да бъде +1 или –1. По тази причина дисбаланс със стойност +2 и –2 също се
допуска в 8/10-битовите кодиращи схеми.
В представените по-горе таблици се съдържат комбинациите, които са използвани съответно за преход от 3-битово в 4-битово и от 5-битово в 6-битово кодиране. Конкатенацията на 4-битови и 6-битови комбинации генерира съответната 10-битовата комбинация. Обърнете внимание, че някои от кодираните стойности имат по две възможни стойности, едната с несъответствие +2, а другата с несъответствие –2. Кодираща схема 8b/10b е създадена с цел перфектно комбиниране на стойностите на 4-битовите и 6-битовите кодове, за да може в най-лошия случай дисбалансът на 10-битова комбинация да бъде +2 или –2. Например 4-битовите кодове с дисбаланс +2 няма да бъдат комбинирани с 6-битови кодове, имащи несъответствие +2, защото това ще доведе до появата на 10-битова стойност с несъответствие +4.
Тъй като най-тежкият случай на
несъответствие на 10-битови кодирани данни е или +2, или –2, все още е възможно
повече 10-битови комбинации с несъответствие +2 или –2 да бъдат предавани чрез
сериен даннов поток. В този случай данновият поток няма да бъде DC-балансиран.
За да се поддържа DC-балансиран даннов поток, всяка кодова комбинация се
конвертира към една от двете възможни стойности, както се вижда в колоните RD-
и RD+ в следващите таблици (RD – Running Disparity) (Изчислен дисбаланс). RD- несъответствие ще бъде
или +2, или 0 (неутрално несъответствие), а RD+ несъответствието ще бъде или
–2, или 0. Кодерът ще вземе една от двете стойности на базата на изчислението
на текущия дисбаланс.
Таблица 5.5.3.1.3 Кодови комбинации за положителен и отрицателен текущ дисбаланс
|
Функция 5B/6B |
|||||||
|
input |
RD
= -1 |
RD
= +1 |
input |
RD
= -1 |
RD
= +1 |
||
|
|
EDCBA |
abcdei |
|
EDCBA |
abcdei |
||
|
D.00 |
00000 |
100111 |
011000 |
D.16 |
10000 |
011011 |
100100 |
|
D.01 |
00001 |
011101 |
100010 |
D.17 |
10001 |
100011 |
|
|
D.02 |
00010 |
101101 |
010010 |
D.18 |
10010 |
010011 |
|
|
D.03 |
00011 |
110001 |
D.19 |
10011 |
110010 |
||
|
D.04 |
00100 |
110101 |
001010 |
D.20 |
10100 |
001011 |
|
|
D.05 |
00101 |
101001 |
D.21 |
10101 |
101010 |
||
|
D.06 |
00110 |
011001 |
D.22 |
10110 |
011010 |
||
|
D.07 |
00111 |
111000 |
000111 |
D.23 |
10111 |
111010 |
000101 |
|
D.08 |
01000 |
111001 |
000110 |
D.24 |
11000 |
110011 |
001100 |
|
D.09 |
01001 |
100101 |
D.25 |
11001 |
100110 |
||
|
D.10 |
01010 |
010101 |
D.26 |
11010 |
010110 |
||
|
D.11 |
01011 |
110100 |
D.27 |
11011 |
110110 |
001001 |
|
|
D.12 |
01100 |
001101 |
D.28 |
11100 |
001110 |
||
|
D.13 |
01101 |
101100 |
D.29 |
11101 |
101110 |
010001 |
|
|
D.14 |
01110 |
011100 |
D.30 |
11110 |
011110 |
100001 |
|
|
D.15 |
01111 |
010111 |
101000 |
D.31 |
11111 |
101011 |
010100 |
|
|
K.28 |
|
001111 |
110000 |
|||
|
Функция 3B/4B |
|||
|
input |
RD
= -1 |
RD
= +1 |
|
|
|
HGF |
fghj |
|
|
D.x.0 |
000 |
1011 |
0100 |
|
D.x.1 |
001 |
1001 |
|
|
D.x.2 |
010 |
0101 |
|
|
D.x.3 |
011 |
1100 |
0011 |
|
D.x.4 |
100 |
1101 |
0010 |
|
D.x.5 |
101 |
1010 |
|
|
D.x.6 |
110 |
0110 |
|
|
D.x.P7 |
111 |
1110 |
0001 |
|
D.x.A7 |
111 |
0111 |
1000 |
|
Контролна променлива |
||
|
input |
RD
= -1 |
RD
= +1 |
|
|
abcdei fghj |
abcdei fghj |
|
K.28.0 |
001111
0100 |
110000
1011 |
|
K.28.1 |
001111
1001 |
110000
0110 |
|
K.28.2 |
001111
0101 |
110000
1010 |
|
K.28.3 |
001111
0011 |
110000
1100 |
|
K.28.4 |
001111
0010 |
110000
1101 |
|
K.28.5 |
001111
1010 |
110000
0101 |
|
K.28.6 |
001111
0110 |
110000
1001 |
|
K.28.7 |
001111
1000 |
110000
0111 |
|
K.23.7 |
111010
1000 |
000101
0111 |
|
K.27.7 |
110110
1000 |
001001
0111 |
|
K.29.7 |
101110
1000 |
010001
0111 |
|
K.30.7 |
011110
1000 |
100001
0111 |
Предавателят
приема отрицателен дисбаланс RD при стартирането. Когато се кодират
8-битови данни, кодерът ще използва колоната RD-. Ако кодираните 10-битовите
данни са с неутрално несъответствие, RD няма да се промени и ще продължи да се
използва колоната RD-. В противен случай, RD ще бъде променен и вместо това ще
се използва колоната RD+. Аналогично, ако текущия RD е положителен и са
кодирани 10-битови данни с неутрално несъответствие, RD все още ще бъде RD+. В
противен случай ще бъде променен от RD+ в RD- и отново ще се използва колоната
RD-. На фигура 5.5.3.1.16 е представен графът за описаното функциониране на
кодера.
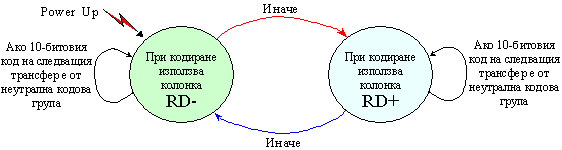
Фиг. 5.5.3.1.16. Схема за определяне на дисбаланса
Всеки байт данни или специален символ има два (възможно еднакви) кода за предаване, т.е. всеки символ за предаване има две изображения. Обяснението за това излишество се състои в това, че 28=256, а 210=1024. В частност <K28.5> може да бъде представен с комбинациите 0011111010 или 1100000101. Коя от двете ще бъде избрана за да бъде предадена, зависи от стойността на “текущия дисбаланс” (Running Disparity, RD).
Двоичният параметър RD се изчислява въз основа на баланса между нулите и единиците в двата подблока. Единицата съответства на сигнала с по-голямо напрежение на контакта “+”, отколкото на контакта “–“ (при медни проводници). Текущият дисбаланс се изчислява след първите 6 бита на предавания символ и след това след последните 4 бита. Дисбалансът може да бъде положителен (повече единици отколкото нули) или отрицателен (повече нули отколкото единици). Тази схема се грижи да поддържа еднакъв броя на единиците и нулите в течение на времето.
Както вече отбелязахме, 10-битовите кодови комбинации са много повече от 8-битовите. По този начин, при получаване на 10-битова последователност, която не съответства нито на D-тип, нито на K-тип, получателят сигнализира за грешка при кодирането. При това, както подателят, така и получателят изчисляват новата стойност на текущия дисбаланс. Ако полученият символ има стойност различна от очакваната стойност на дисбаланса (която получателят изчислява въз основа на предидущата), то получателят сигнализира за грешка при дисбаланс. Показано е, че вероятността за грешка при предаване е съизмерима с числото 10-12.
Високо скоростният последователен протокол на PCI Express вгражда тактовите сигнали в кодираните данни и така осигурява самосинхронизация. Прилаганият алгоритъм 8/10 бита осигурява разбиването на последователността от нули и единици по такъв начин, че приемната страна да не загуби границите на отделните битове. Шината осигурява предаването на управляващи съобщения, в това число и прекъсвания, по същите даннови линии. Последователният протокол не предвижда блокиране, ето защо лесно се осигурява латентност (задръжка), съпоставима с PCI, в която има отделени линии за прекъсване.
В процеса на инициализация, всеки от PCI Express каналите автоматично установява честотата и ширината си, в съответствие с възможностите на агентите, намиращи се в края на канала, при това без използване на софтуер.
Слой
“Link”
Основната задача на това ниво е да осигурява правилно предаване на данните в PCI Express каналите. Това ниво отговаря за цялостността на данните, като за целта добавя към пакета данни поредния номер и контролния код CRC, по начина, показан на фигура 5.5.3.1.17.
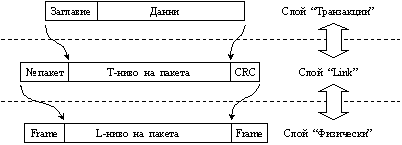
Фиг. 5.5.3.1.17. Схема за добавяне на данновите признаци в отделните слоеве на обработка
Повечето от пакетите се инициализират в нивото на транзакциите (описан по-долу). Протоколът предава пакетите само в случай, че приемащият буфер е свободен, с което се избягват повтарящи се транзакции и се разтоварва шината. Повторното предаване на повредени пакети се осигурява от нивото “Link”.
Слой
“Транзакции”
В този слой се получават заявките за запис или за четене от програмното ниво и се формират пакетите от заявки за предаване в нивото “Link”. Някои заявки изискват потвърждение и нивото на транзакциите има грижата за получаването на ответните пакети от физическото ниво. На това ниво всеки пакет се снабдява със заглавна част с уникален идентификатор и степен на приоритет. Всеки пакет има уникален идентификатор, който позволява да се изпрати ответният пакет по правилен адрес. Форматът на пакетите поддържа 32 и 64 битова адресация. Предвидени са три нива на приоритет:
· No-snoop. Означава отсъствие на всякакъв приоритет. Пакет с такъв маркер се предава последен в опашката ;
· Relaxedordering. Пакет със среден приоритет. Такива пакети се предават последователно, изпреварвайки предходните ;
· Priority. Такива пакети се предават най-напред.
Тази организация позволява реализацията на сложни алгоритми за оптимизация на потоците от данни с различна степен на значимост, каквито създават мултимедийните приложения например.
Форматът на PCI Express пакетът е показан на следващата фигура.
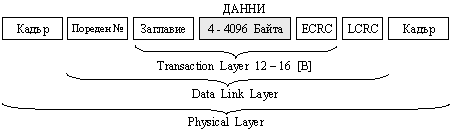
Фиг. 5.5.3.1.18. Формат на пакет по PCI Express шината
Нивото на транзакциите поддържа 4 адресни пространства – три “PCI-пространства” (Памет, Входно-изходно I/O и Конфигурационно) и пространство на съобщенията (Message Space). В стандарта PCI 2.2 съществува алтернативен начин за разпределение на системните прекъсвания, наречен MSI (Message Signaled Interrupt). Спецификацията на PCI Express използва тази концепция в качеството й на основен метод за разпределение на прекъсванията.
Програмен
слой
Програмната съвместимост има важно значение за третото поколение входно-изходни шини. Съществуват два аспекта на програмната съвместимост: инициализация и по време за изпълнение. PCI има отработен модел за инициализация, с помощта на който операционната система е в състояние да намери всички допълнителни устройства и оптимално да им разпредели системни ресурси (памет, прекъсвания и пр.). Този модел е запазен и в PCI Express, следователно изменения в операционната система не се налагат. Освен това в системи с PCI Express се поддържа и времевият модел за изпълнение, което означава, че изменения не са необходими и в потребителските приложения. Това не пречи новите потребителски приложения да използват новите възможности на PCI Express.
Архитектура PCI Express отговаря на всички изисквания, предявени към третото поколение входно-изходни системи. Нейните разширени функции и мащабируема производителност ѝ позволяват да стане унифицирано решение за множество платформи – настолни, мобилни, сървърни, устройства за връзка и вграждащи се устройства. Едно от концептуалните отличия на интерфейса PCI Express, което позволява същественото увеличение на производителността на системата това възможността при свързване на крайни устройства да се приложи топология “звезда” (вижте фигурите 5.5.3.1.7 и 8). Каналът (Link), свързващ крайно устройство с комутатора (switch), представлява съвкупност последователни еднобитови дуплексни линии, наричани линии (Lanes). Пропускателната възможност на линиите може да бъде линейно мащабирана (x2 link), (x4 link), … , (32 link). Слотът обаче може да бъде по-широк от подведения към него канал, т.е. на слот х16 фактически може да бъде въведен канал х8 и пр. По този начин една карта, чиято линия е х4, следва да работи нормално в слот с ширина на линията х8 и повече. Съгласуващата канала PCI Express процедура осигурява максимално възможната ширина на линията за работа. При предаване на данни по канали с много линии се прилага последователно разсейване на данните (вижте фигура 5.5.3.1.14).
Следващият
раздел е:
5.5.3.2 Хъбова
архитектура на входно-изходната система